从理论到武器:2026 上半年 AI 攻击能力质变全梳理
5 个月前,研究者用 44 条 prompt 引导 AI 写出一个内核 exploit;5 个月后,AI 代理 31 秒自主修复了被自己搞坏的登录函数。这中间到底发生了什么?
导语:一条数据钩子和一个首尾对比
先看一条让我盯了很久的数据。
根据 AI 研究机构 Epoch AI 在 2026 年 7 月 2 日发布的报告,2026 年 6 月,全球共披露约 1500 个高危/关键级别 CVE,覆盖微软、谷歌、苹果、Adobe、Oracle、Cisco 等 21 家主要机构。这个数字,相当于 Mythos 发布前月度最高纪录的 3.5 倍以上9。
注意 Epoch AI 自己也很谨慎——它在标题里写的是”与 Claude Mythos 发布时间相关”,而不是”由 Mythos 导致”。相关不等于因果,这一点我们后面会反复回到。
但仅仅这条数据,已经足够让我们回头做一次时间线梳理了。
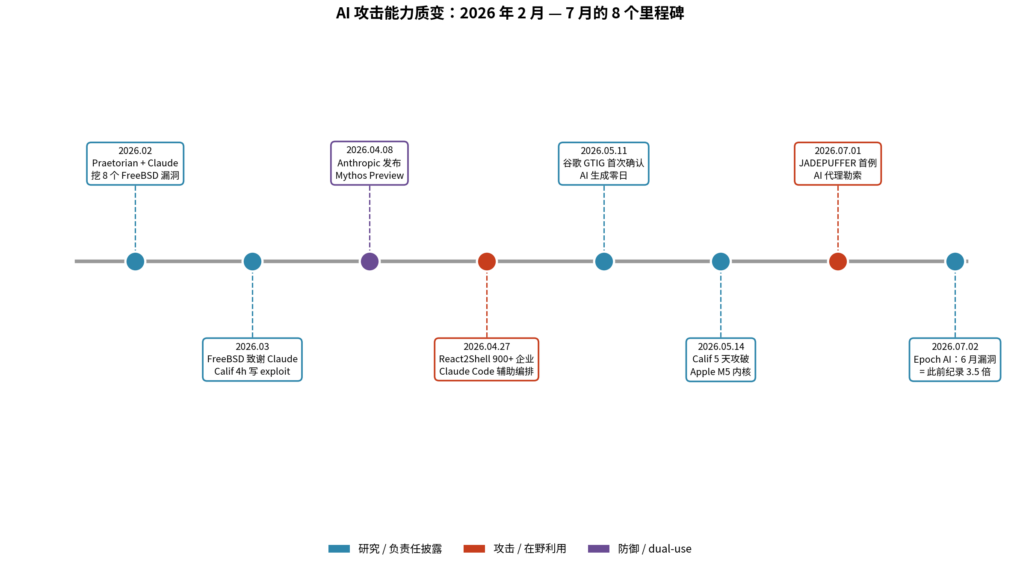
把时钟拨回 5 个月前。2026 年 2 月,安全公司 Praetorian 用 Claude Opus 4.6 配合 Claude Code,在 FreeBSD 内核里挖出 8 个漏洞——这是这次”质变”叙事里能找到的最早一个清晰节点。当时研究者要给 AI 44 条 prompt,一点点引导它写出一个可用的内核 exploit。
而 5 个月后,2026 年 7 月 1 日,Sysdig 披露的 JADEPUFFER 勒索攻击中,AI 代理在攻击过程里,用 31 秒自主修复了一个自己之前写崩的登录函数——没有任何人在旁边指挥它。
从”44 条 prompt 才能写出 exploit”到”31 秒自主修复一个被自己弄坏的脚本”,这 5 个月到底发生了什么?这篇文章把这条线上的 8 个关键事件,按时间顺序梳理一遍。
01 序章:5 个月前的”理论威胁”
故事从 2026 年 2 月开始。
安全公司 Praetorian 发了一篇博客,标题就叫《AI Vulnerability Research on the FreeBSD Kernel》1。他们做的事说起来并不复杂:让 Claude Opus 4.6 配合 Claude Code,去审计 FreeBSD 内核代码。结果是挖出了 8 个内核漏洞,其中 CVE-2026-3038 已经公开修复。
这件事有几个细节值得记一下。
第一,他们用的是普通的 Claude 订阅(Claude Pro Max,约 100 美元/月),不是什么政府级别的高级权限。换句话说,门槛没大家想象的那么高。
第二,整个过程走的是”负责任披露”流程——发现问题先通知厂商,等修复了再公开。这是研究姿态,不是攻击姿态。
第三,也是更有意思的一点:在 2026 年 3 月 26 日发布的 FreeBSD 官方安全公告(FreeBSD-SA-26:08.rpcsec_gss)里,致谢栏出现了这么一行字——
“Nicholas Carlini using Claude, Anthropic”
Nicholas Carlini 是 Google DeepMind 的研究员,也是机器学习安全领域的知名学者。FreeBSD 把他列为 CVE-2026-4747(RPCSEC_GSS 远程内核 RCE)的发现者,并明确写了他用的是 Anthropic 的 Claude2。这是开源操作系统官方公告里第一次出现”用 AI 发现漏洞”的致谢。
不过,要客观看待这件事的难度。需要补充一个事实:FreeBSD 14.x 默认没有启用 KASLR(内核地址空间布局随机化),也没有 stack canary(栈溢出保护)。这些在现代 Linux 上几乎是标配的防护机制,在 FreeBSD 上是缺位的。换句话说,FreeBSD 的攻击面相对大一些,这降低了 AI 找漏洞和写利用的难度。
当时舆论对这件事的定性基本是——”AI 在漏洞研究领域的理论威胁被证实了”。注意”理论”这两个字。那时候大家讨论的还是’AI 能不能做’,而不是’AI 已经在做什么’。短短几个月后,这个词就改了。
02 转折点:4 小时写出一个内核 RCE
真正让”理论威胁”变成”实操工具”的,是 Calif。
Calif 是一个安全研究博客。2026 年 3 月 31 日,他们发了一篇文章,标题翻译过来大概是《MAD Bugs:Claude 写了一个完整的 FreeBSD 内核 exploit》3。做的事情直接粗暴——
他们让 Claude 针对 CVE-2026-4747(就是前面 Carlini 用 Claude 发现的那个漏洞)写出一个可用的远程内核 RCE exploit。
时间消耗是这样的:约 8 小时挂钟时间,其中 实际有效工作大约 4 小时。
这里有几个细节必须说清楚,否则非常容易被误读:
第一,这”4 小时”是 exploit 的编写时间,不是漏洞的发现时间。漏洞是 Carlini 先发现的,Calif 是在已知漏洞存在的前提下,让 AI 去写利用代码。两件事的难度完全不在一个量级。
第二,Calif 并不是”完全无人工干预”。他们在博客里明确说,自己一共给了 Claude 44 条 prompt——研究者全程在引导、纠正、提供方向。这不是”AI 一键生成 exploit”,而是”AI 在一个懂行的人手里,变成了一个非常高效的助手”。
第三,Calif 自己在博客里给这件事贴了一个标签——“首个由 AI 同时发现并利用的远程内核 RCE”。注意,这个表述是 Calif 的自称,不是行业共识级别的定性。但它确实是一个清晰的标志:AI 写出来的 exploit 已经能在真实 CVE 上跑通,不再是 demo。
这件事之后,安全圈关于 AI 在攻防两端的能力讨论,画风就变了。从”理论上能不能”,变成了”实际效率有多高”。
03 分水岭:Mythos Preview 与攻防悖论
如果说前两件事还只是研究者在玩,2026 年 4 月 8 日 Anthropic 的动作,让这件事正式进入了平台级别。
这一天,Anthropic 通过一个叫 Project Glasswing 的项目,正式向外界推出 Mythos Preview4。
关于 Mythos Preview,有几个事实需要准确陈述:
第一,按照 Anthropic 自己的描述,这是一个 “general-purpose, unreleased frontier model”(通用、未公开发布的前沿模型),定位是 dual-use(双用途)——既可用于尖端编码,也可用于漏洞研究。Anthropic 明确表示 不计划公开发布。
第二,分发对象是经过筛选的:通过 Project Glasswing,向 AWS、Apple、Cisco、Google、Microsoft 等 12 家合作伙伴,以及 40 多家关键基础设施机构开放。同时承诺提供 1 亿美元的使用额度和 400 万美元的开源安全工具捐赠。
第三,Anthropic 自称 Mythos 已经发现了 “数千个高危漏洞”——这个数字没法独立验证,只能听厂商自己说。
这件事的结构性矛盾非常明显,也是它最值得讨论的地方:
Anthropic 既是 AI 公司,又通过自己的模型去防御 AI 可能带来的威胁——它一边在造武器,一边在卖盾牌,而这两件事用的是同一个东西。
业界管这个叫”dual-use 双用途困境”。漏洞研究模型本身是中性的——研究者和攻击者拿到的能力是一样的,区别只在于你怎么用。Anthropic 选择”只分发给经过筛选的伙伴”这种保守路线,本质上就是在试图管理这个风险:不让模型公开发布,但让关键基础设施防御方能拿到。
这种姿态能否真的化解 dual-use 风险,目前还没人能给答案。但 Mythos 一旦存在,攻防双方的天平就开始倾斜了——后面几件事,会让大家看清往哪边倾斜。
04 攻击端上场:React2Shell 与”AI 辅助”红线
接下来这件事,是这条时间线上 第一次明确出现”AI 工具被用在攻击端”的案例。也是这篇文章里我必须最谨慎处理的一段。
2026 年 4 月 27 日,封面新闻记者雷强发了一篇报道,引述了 360 安全专家对一波大规模攻击的预警5。
攻击的主角是一个被叫作 React2Shell 的漏洞利用链,对应的 CVE 是 CVE-2025-55182。这里有一个细节需要说清楚:这个漏洞本身是 2025 年 12 月的旧漏洞,2026 年 4 月出现的是新一波利用——攻击者重新包装了利用方式,规模比之前大得多。
报道里提到的几个事实:
- 攻击者使用了一个叫 Bissa scanner 的自动化工具,配合 Telegram 机器人进行调度;
- 截至 4 月 27 日,已经有 900 多个成功利用案例,受害者覆盖金融、加密货币、零售等行业。
但最让我盯住的,是报道中关于 AI 工具的那段措辞。这一段必须 逐字保留,不能改写:
“并引入 Claude Code、OpenClaw 等 AI 辅助工具,用于支撑攻击脚本编写、流程编排和效率提升。”
请仔细读这段话。
第一,它说的是 “AI 辅助工具”,不是”AI 自主攻击”。Claude Code、OpenClaw 在这里的角色是 编程辅助——攻击者拿它们来写脚本、做流程编排、提升效率,跟开发者拿它们写正常代码的用法没有本质区别。
第二,整个攻击链是 人在指挥:选定目标、决定何时出手、决定如何变现——这些都是人做的。AI 工具只参与了”代码层面”的工作。
第三,OpenClaw 本身是一个开源 AI 编程框架,它自己之前都曾被 CNNVD 通报过漏洞——一个工具能被用来干坏事,并不意味着这个工具本身是恶意的。
这个公众号之前写过 Claude Code 和 OpenClaw 的教程,所以这件事对我们读者来说有一个特别的意义——它把一个抽象问题摆到了桌面上:
工具是中性的,决定性质的是使用方式。 同一个 Claude Code,开发者拿它写业务代码、研究者拿它审计内核、攻击者拿它写利用脚本——三种用法,三种性质,但工具是同一个。
👉 如果你想看这两个工具的”正当用法”,可以翻我之前写过的两篇教程:
- 《Claude Code 国内使用入门教程》 —— 国内可用的配置和上手流程
- 《OpenClaw 技能完全指南:从安装到实战》 —— 22 个精选技能的完整地图
同一个工具,用法决定性质——读完那两篇,再回头看这一节,会更清楚这条红线的位置。
这件事之后,”AI 攻击能力质变”叙事里,攻击端第一次明确有了姓名。
05 加速期:5 月的两记重锤
接下来这两件事,每一件都让”质变”这个词更扎实。
第一锤:谷歌 GTIG 首次确认 AI 生成零日
2026 年 5 月 11 日,谷歌威胁情报组(Google Threat Intelligence Group,GTIG)发了一篇博客,标题是《Adversaries Leverage AI for Vulnerability Exploitation for Initial Access》6。
这篇博客里有一个特别关键的措辞——GTIG 用了 “For the first time”(首次)。这是 官方威胁情报团队第一次明确确认,AI 被用于生成零日漏洞利用。
事实细节是这样:
- 目标是一个 未被点名的开源 Web 系统管理工具;
- 攻击者用一段 Python 脚本绕过了双因素认证(2FA);
- 攻击 被挫败了——GTIG 联合厂商走了负责任披露流程,没有造成大规模损失;
- GTIG 判断”AI 参与了”的依据很特别:脚本里包含了 教学性的 docstring(代码注释写得像教材),还附了一个 虚构的 CVSS 评分——这两个特征强烈暗示代码是 LLM 生成的;
- 谷歌把这个判断标注为 “high confidence”(高置信度)。
这里有一个 必须澄清的事实——前期不少自媒体在传”GTIG 排除了 Mythos 和 Gemini”。这是错的。
GTIG 原文里只写了 “Although we do not believe Gemini was used”(虽然我们认为没有被使用的是 Gemini),全文 没有出现 Mythos 这个词,也没有排除 Anthropic Mythos。所以准确的说法应该是:GTIG 只排除了自家 Gemini,至于用的是哪个 AI,没有点名。
读者在转载这类新闻时,多注意这种细节。
第二锤:Calif 用 Mythos 5 天攻破 Apple M5 内核
第二锤来自我们前面提过的 Calif。2026 年 5 月 14 日,他们又发了一篇博客,标题翻译过来是《首个公开的 Apple M5 macOS 内核内存破坏 exploit》7。
这件事的背景信息很关键:
- 研究员阵容:Bruce Dang(4 月 25 日发现 bug)、Dion Blazakis(4 月 27 日加入)、Josh Maine(负责工具链)——三位都是业界知名研究员;
- 5 天周期:从 4 月 25 日发现 bug,到 5 月 1 日完成 PoC,正好 5 天;
- 目标:Apple M5 芯片,运行 macOS 26.4.1,启用了 MIE;
- MIE 是什么:全称 Memory Integrity Enforcement(内存完整性强制),基于 ARM MTE 实现——不是网上一些文章写的”Memory Isolation Engine”。
Calif 博客里有这么一段话,值得原样引用:
“Apple spent five years building hardware and software to make memory corruption exploits dramatically harder. Our engineers, working together with Mythos Preview, built a working exploit in five days.”
翻译过来就是:苹果花了五年做硬件和软件的纵深防御,让内存破坏类 exploit 变得极其困难;而我们的研究员配合 Mythos Preview,5 天就搞出来了。
Calif 还有一句话也很有味道,原样留着:
“Apple built MIE in a world before Mythos Preview. We’re about to learn how the best mitigation technology on Earth holds up during the first AI bugmageddon.”
不过几个限定词必须加上:
第一,“首个公开的 M5 macOS 内核利用”是 Calif 自称,目前完整 55 页报告要等苹果修复后才会公开,现在的陈述都是 Calif 单方面。
第二,Calif 自己也在评论里抛出过一句”反炒作”的话:他们说这次的 exploit 在技术层次上”只是 90 年代水平的 exploit“。换句话说,他们承认这事在技术上没那么神,但 AI 把它从’人写不出来’变成’5 天就能写出来’,这件事本身才是真正的信号。
06 质变完成:7 月的 AI 代理勒索与 3.5 倍漏洞海啸
5 个月后的 7 月,”质变”叙事里最后两块拼图到位了。
第一块:JADEPUFFER——首个被记录的 AI 代理勒索
2026 年 7 月 1 日,云安全公司 Sysdig 发了一篇博客,披露了一起代号 JADEPUFFER 的攻击事件8。Sysdig 给它的定性是——
“first documented case of agentic ransomware”
中文里我把它表述成 “首个被记录的 AI 代理勒索攻击”——加”被记录的”几个字,是因为绝对化的”全球首例”我们没法证实,也许之前有过但没被披露。
事件的事实链非常清晰:
- 入口漏洞:CVE-2025-3248,Langflow 的未授权远程代码执行(影响 1.3.0 之前版本,触发点是
/api/v1/validate/code这个接口); - 完整攻击链:
- 通过 Langflow 漏洞入侵;
- 窃取 LLM、云、数据库的凭证;
- 横向移动到生产服务器;
- 利用 Nacos 的 CVE-2021-29441 配合 默认 JWT,进一步获取权限;
- 拿到 MySQL root 权限;
- 加密 1342 条 Nacos 配置;
- 最后 DROP DATABASE——直接把数据库删了,留下勒索信息。

但这次最让人盯住的,不是攻击链本身,而是 Sysdig 给出的 4 条”AI 代理自主性”证据:
- 自然语言注释:脚本里出现了用人话写的注释——传统自动化攻击不会这样写;
- 31 秒修复登录:AI 代理在攻击过程中,自己之前把登录函数写崩了,31 秒内自主定位并修复——没有任何人干预;
- 理解自由文本上下文:能根据环境里的非结构化文本信息做判断;
- 600+ payload 压缩执行:把 600 多个 payload 压缩成更高效的执行序列。
第 2 条是真正的标志性事件。回头看我们的导语——5 个月前研究者需要给 AI 44 条 prompt 才能完成一个 exploit,5 个月后 AI 代理在 31 秒里自主完成了对自己代码的修复。这就是”质变”最直观的尺度。
第二块:Epoch AI 的 3.5 倍数据
回到开头那条数据。
2026 年 7 月 2 日,Epoch AI 发布了那份 CVE 激增报告9。
这里有一个 必须澄清的事实——前期一些文章把 Epoch AI 描述成”网络安全公司”,这是错的。Epoch AI 是一家 AI 研究机构,自我定位是”Investigating the trajectory of AI”(追踪 AI 的发展轨迹),主要做 AI 趋势研究。它不是赛门铁克、不是卡巴斯基,它看 CVE 数据是从 AI 能力发展的视角,不是从威胁情报视角。
报告里的几个关键数据:
- 2026 年 6 月,全球共披露约 1500 个高危/关键 CVE;
- 涉及 21 家主要机构:Microsoft、Google、Apple、Adobe、Oracle、Cisco 等;
- 这一数字相当于 Mythos 发布前月度最高纪录的 3.5 倍以上;
- 报告标题明确写了”与 Claude Mythos 发布时间相关“。
注意 Epoch AI 自己的措辞——是 “相关”,不是 “导致”。Epoch 自己在报告里也明确说明这是相关性,不是因果性。
为什么这么说?因为漏洞披露数量激增,可能有很多原因:可能是 Mythos 让研究效率真的提高了;可能是 Mythos 这个事件本身让整个研究社区更关注漏洞挖掘;也可能是 6 月恰好赶上一些大型厂商的季度披露周期;还有可能是多种因素叠加。
单一归因到 Mythos 头上,是不严谨的。 Epoch 自己都克制,我们作为科普作者更应该克制。
但即便如此,”3.5 倍”这个数字依然是一个非常重要的信号——它告诉我们,前面这 5 个月发生的事情,正在以可见的方式重塑漏洞披露的节奏。
安全/风险提示
讲到这里,必须做一个冷静的暂停。
第一,AI 攻击不等于 AI 觉醒。前面提到的所有事件,AI 都是 工具——要么是研究者在用,要么是攻击者在用,要么是在沙箱化的代理框架内运行。”AI 自己决定攻击谁”这种科幻场景,目前没有任何被证实的事实。
第二,Mythos Preview 普通用户接触不到。它不公开发布,只通过 Project Glasswing 分发给经过筛选的伙伴和关键基础设施机构。所以自媒体里那些”Mythos 即将开放下载、全网恐慌”的标题,基本可以判定为夸大其词。
第三,真正高频的现实威胁,仍然是未修复的旧漏洞。React2Shell 利用的 CVE-2025-55182 是 2025 年 12 月的旧漏洞,JADEPUFFER 利用的 CVE-2025-3248 也是早就修复了的。大部分攻击者根本不需要 AI,他们靠的就是企业不及时打补丁。
实用建议
给普通读者的三件事
- 及时更新。无论是服务器、路由器还是 App,能升级就升级。Mythos 让漏洞被发现的概率变高了,意味着你每拖一天,风险都在变大。
- 凭证卫生。JADEPUFFER 攻击链里的关键一环是 默认 JWT 凭证——很多人装完系统默认配置就直接上线了。所有默认凭证都要换,所有 2FA 都要开。
- 冷静看标题。看到”AI 黑掉 XX””AI 自主攻击”这种标题,先问自己三个问题:是人在指挥还是 AI 自主?是 exploit 编写还是漏洞发现?是研究姿态还是攻击姿态?大部分标题党,问完这三个问题就现形了。
给开发者的三件事
- AI 找漏洞已经是生产级能力。Praetorian 用 100 美元/月的订阅挖出 8 个 FreeBSD 内核漏洞——这个事实意味着,你自己代码里的漏洞,AI 也能找到。
- 自己先 AI red-team 一遍。在提交产品之前,用 Claude Code、OpenClaw 这类工具对自己的代码做一次审计——找到漏洞的应该是你,而不是攻击者。
- 关注厂商 advisory。FreeBSD、Apple、Microsoft、Google 这些厂商的安全公告现在开始频繁提到 AI——读懂它们在说什么,比刷朋友圈的二手消息重要得多。
常见问题 Q&A
Q1:Mythos 能黑我的电脑吗?
不能直接黑。Mythos 不公开发布,普通用户接触不到;能接触到的只有经过筛选的 12 家合作伙伴和 40+ 关基机构。真正威胁到你的不是 Mythos 本身,而是 Mythos 让 整个研究社区发现漏洞的速度变快了——你之前没修的旧漏洞,未来被发现和利用的概率提高了。
Q2:作为普通用户,怎么防御?
三件事:及时更新所有设备和应用、关闭所有默认凭证并启用 2FA、不要轻信”AI 觉醒”的标题党。90% 的攻击者根本不需要 AI,他们靠的就是你不打补丁。
Q3:Anthropic 既造 Mythos 又帮大家防御,是不是既当裁判又当运动员?
是的,这就是 dual-use 双用途困境的核心矛盾。Anthropic 既是 AI 公司,又通过 Mythos 帮助关键基础设施防御——这两件事用的是同一个模型。目前没有任何完美的解决方案,Anthropic 选择的”不公开发布 + 受控分发”路线,是目前能看到的最保守的策略。
Q4:我应该担心 AI 觉醒然后攻击人类吗?
不需要。本文提到的所有事件里,AI 都是 工具——研究者在用、攻击者在用、代理框架在跑。”AI 自主决定攻击目标”目前没有任何被证实的事实。真正该担心的,是人怎么用 AI,而不是 AI 自己想干什么。
参考资料
[1] Praetorian – AI Vulnerability Research on the FreeBSD Kernel – https://www.praetorian.com/blog/ai-vulnerability-research-freebsd-kernel/
[2] FreeBSD Security Advisory SA-26:08.rpcsec_gss(致谢 Nicholas Carlini using Claude, Anthropic)- https://www.freebsd.org/security/advisories/FreeBSD-SA-26:08.rpcsec_gss.asc
[3] Calif (MAD Bugs) – Claude Wrote a Full FreeBSD Kernel Exploit – https://blog.calif.io/p/mad-bugs-claude-wrote-a-full-freebsd
[4] Anthropic – Project Glasswing(Mythos Preview 公告)- https://www.anthropic.com/glasswing
[5] 封面新闻 – 360 专家预警 React2Shell 大规模攻击(2026-04-27,记者雷强)- https://view.inews.qq.com/a/20260427A06IDP00
[6] Google GTIG – Adversaries Leverage AI for Vulnerability Exploitation(2026-05-11)- https://cloud.google.com/blog/topics/threat-intelligence/ai-vulnerability-exploitation-initial-access
[7] Calif – First Public macOS Kernel Memory Corruption Exploit on Apple M5 – https://blog.calif.io/p/first-public-kernel-memory-corruption
[8] Sysdig – JADEPUFFER Agentic Ransomware(2026-07-01)- https://www.sysdig.com/blog/jadepuffer-agentic-ransomware-for-automated-database-extortion
[9] Epoch AI – CVE Severity Spike After Claude Mythos(2026-07-02)- https://epoch.ai/data-insights/cve-severity-spike
5 个月时间,从”理论威胁”到”31 秒自主修复”。AI 在攻防两端的能力曲线已经拐弯——这不是恐慌的理由,但确实是认真对待的信号。
如果你觉得这篇梳理有帮助,欢迎转发给同样被各种”AI 攻击”标题轰炸过的朋友——把事实摆清楚,比传播恐慌更重要。
📚 延伸阅读
想更系统地理解本文提到的工具和趋势,推荐结合下面几篇一起看(难度递进):
- 《Claude Code 国内使用入门教程》 —— 本文反复提到的 Claude Code,国内怎么正当用,入门第一篇
- 《OpenClaw 技能完全指南:从安装到实战》 —— 同样被攻击者”借用”的 OpenClaw,它的完整能力地图
- 《AI 编程套餐怎么选:2026 中外 Coding Plan 全对比》 —— 想自己上手 AI 编程,先搞清楚选哪家
- 《Claude Code 源码解密:它不只是个会写代码的 AI》 —— 进阶:从源码层面看 Claude Code 到底在做什么
作者:Merlin | 发布日期:2026.07.05