DeepSeek速度狂飙4倍还不丢精度
每一次 Token 选择都是一次海底捞针,而 HISA 找到了更聪明的搜索策略
导语
大模型处理超长上下文时,就像在海边、沙哈拉沙漠里找一粒特定的沙子——传统方法需要翻遍每一粒沙,而 HISA 学会先锁定可能存在沙子的区域,再精准挖掘。北大团队提出的分层稀疏注意力方法,无需任何训练,在 128K 上下文场景实现 4 倍加速,同时保持超过 99% 的选择质量。1
01 从”全员投票”到”代表开会”:稀疏注意力的困境
要理解 HISA,先理解它解决的是什么问题。
现代大模型(如 DeepSeek-V3.2、GLM-5)处理长文本时,面临一个经典难题:注意力机制的计算量随上下文长度平方增长。一个 128K token 的上下文,意味着每次推理都要在 128K × 128K 的矩阵上计算相似度——这在工程上几乎是不可接受的。
👉 关联阅读:《DeepSeek 深度解析:技术突破、争议与行业影响》 — V3/R1 时代的技术路线与资本背景,了解 HISA 诞生的技术语境
业界的解决方案是 DeepSeek Sparse Attention(DSA):对于每个查询(Query),不是让它与所有 prefix token 计算注意力,而是先打分、然后只保留分数最高的 top-k 个 token 做精细注意力。这个做法让计算量从 O(L²) 下降到 O(L·k),代价是额外需要一个 indexer 模块 来完成”打分→选 top-k”的工作。
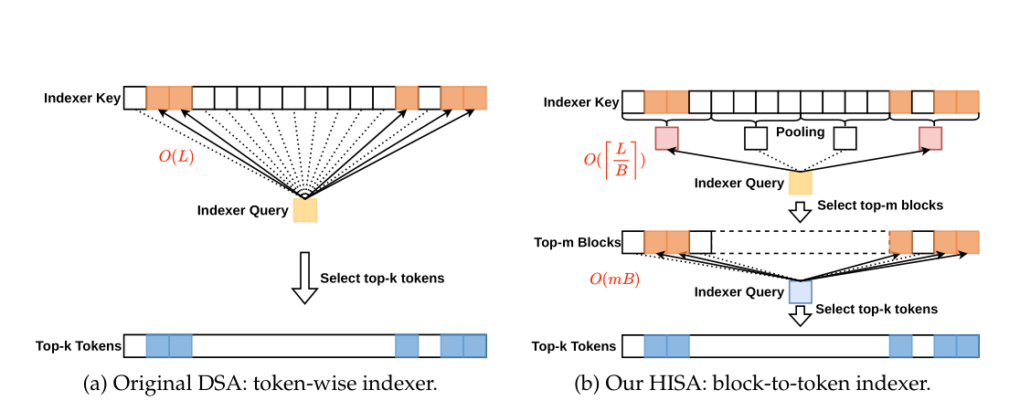
图1:原始 DSA 的 token 级 indexer(左侧 flat 扫描)与 HISA 两阶段分层 indexer(右侧 block 级初筛 + token 级精筛)对比 1
问题恰好出在这个 indexer 上。indexer 本身需要扫描整个 prefix 才能打分选 token——这意味着 indexer 的复杂度仍是 O(L²)。当上下文从 4K 增长到 128K 甚至 1M 时,原本可忽略的 indexer 开销逐渐成为主要瓶颈。1
这就是 HISA 要解决的核心问题:如何让 indexer 也变快?
02 两阶段筛选:先”分区扫描”再”精准命中”
HISA 的核心思想非常符合直觉:如果无法加速单次扫描,就用分层扫描减少扫描范围。
第一阶段:Block 级初筛
将 prefix 分成固定大小的块(block size B=128),每个块用一个”代表向量”(pooled representative)来概括整块内容。然后,Query 只需要对所有 block 的代表向量打一次分,就能快速选出最相关的 top-m 个块。
这个阶段的工作量是 O(L²/B),因为 block 数量只有 token 数量的 1/B。
第二阶段:Token 级精筛
在选中的 top-m 个块内部,运行原始的 DSA indexer——从最多 m×B 个 token 中精确选出 top-k 个。
这阶段的复杂度是 O(m·B·L) = O(L·m·B)。
两阶段加起来总复杂度为 O(L²/B + L·m·B),相比于原始的 O(L²),当 L 很大时提升显著——以 128K context 为例,实测达到 4 倍 kernel 延迟降低。1
👉 关联阅读:《刚刚,DeepSeek V4 来了》 — 了解 V4 的核心架构升级(CSA 混合注意力、三档推理模式),与 HISA 的长上下文优化思路互相印证
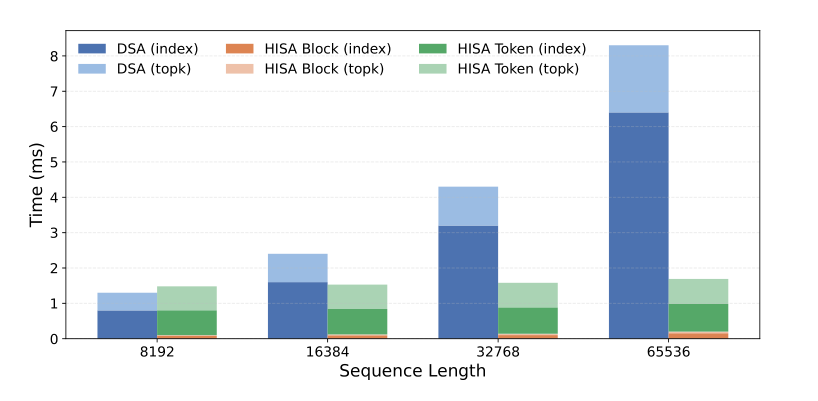
图2:Indexer kernel 延迟对比。Query chunk size=1024,block size B=128,top-m=64 blocks,top-k=2048 tokens。HISA 在 128K 上下文达到约 4× 加速 1
03 数据说话:加速不降质量
HISA 团队在多个维度验证了方法的有效性:
加速效果(Kernel 延迟)
| 上下文长度 | 加速比 |
|---|---|
| 32K | 2× |
| 128K | 4× |
需要特别说明的是:indexer 耗时在总注意力时间中占比随上下文变长而增加,因此加速效果在更长上下文下更明显。1
质量保证(Token Selection 质量)
更关键的问题是:快速初筛会不会漏掉真正重要的 token?
实验显示,HISA 选出的 token 集合与原始 DSA 的 token 集合 mean IoU 超过 99%——也就是说,几乎一样,但快了很多。1
Needle-in-a-Haystack 测试
这是大模型长上下文能力的”试金石”:在一本百科全书里藏一根针,让模型找出来。结果 HISA 几乎与原始 DSA 持平,而传统 block-sparse 方法则明显落后——粗粒度的 block 筛选确实会漏掉细粒度的重要 token。1
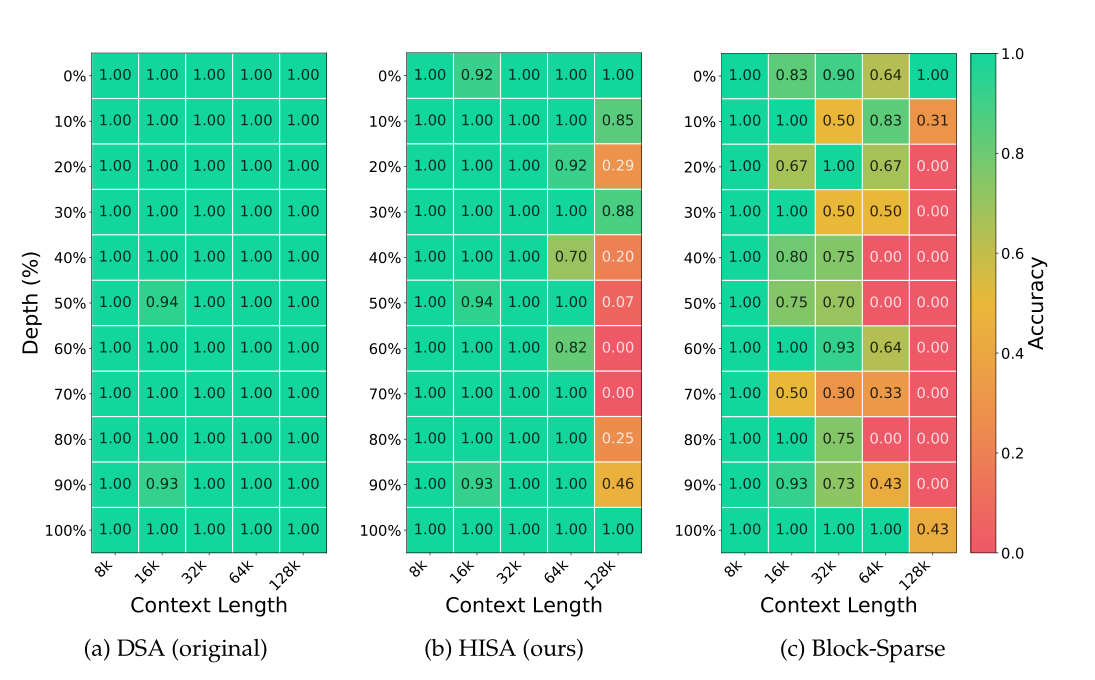
图3:Needle-in-a-Haystack 检索准确率热力图。(a) 原始 DSA,(b) HISA,(c) Block-Sparse。HISA 几乎与 DSA 持平,而 Block-Sparse 在深层次明显落后 1
04 为什么 HISA 比 Block-Sparse 更高明?
你可能听说过 MoBA、NSA 等 block-sparse 注意力方法,它们也是用分块来降低计算量。那么 HISA 和它们的核心区别在哪?
| 方法 | 粒度 | 注意力范围 |
|---|---|---|
| Block-Sparse (MoBA/NSA) | Block | 整个 block 全部参与 |
| HISA | Block 初筛 + Token 精筛 | 精确的 top-k token |
Block-sparse 方法在 block 粒度做稀疏,block 内所有 token 都参与注意力——这限制了稀疏率的下限。而 HISA 的 block 层只是”初筛”,最终参与注意力的仍是精确的 token 级别 top-k,保持了 DSA 的细粒度优势。1
👉 关联阅读:《一文读懂 AI Agent 技术架构》 — 从原理到实践,全面理解 AI Agent 的设计模式与工程实现,理解注意力机制在 Agent 系统中的角色
用一个比喻:
Block-sparse 像是”选择哪些章节来读”——你读一章就得读完整章。 HISA 则是”先划定重点章节,再从章节里挑关键段落”——精度和效率兼得。
05 实战:如何快速上手 HISA
HISA 是一个完全无需训练(training-free)的模块替换方案。如果你的系统使用了 DSA 类型的稀疏注意力,替换路径非常清晰:
Step 1:确认你的稀疏注意力实现
HISA 适用于 token-level top-k 选择范式的稀疏注意力(如 DeepSeek-V3.2/GLM-5 中的 DSA)。
Step 2:集成 HISA indexer
将原有的 flat token scan indexer 替换为 HISA 的两阶段 indexer。Block size B=128、top-m 块数可根据延迟-质量 tradeoff 调整。
Step 3:下游模块无需修改
HISA 输出的是与原始 DSA 完全一致的 per-query k token indices,下游 Sparse MLA 等模块完全透明。
💡 实践建议:如果你的应用场景超过 32K token,建议优先尝试 HISA;32K 以下收益相对较小,可以先 profile 确认 indexer 瓶颈后再决定。
👉 关联阅读:《Hermes Agent 和 OpenClaw 到底选哪个?》 — 会”越用越聪明”的 AI 助手,解析 AI Agent 的自我进化机制,感受 HISA 这类底层优化如何影响上层 Agent 体验
常见问题 Q&A
Q:HISA 和 MoBA/NSA 有什么区别?
A:MoBA/NSA 在 block 粒度做稀疏选择,block 内所有 token 都参与注意力。而 HISA 的 block 层只是”初筛”,最终注意力仍是 token 粒度的 top-k,精度更高。
Q:HISA 需要训练吗?
A:完全不需要。HISA 是 training-free 的模块替换方案,直接替换 indexer即可,无需修改模型权重或重新训练。
Q:哪些场景不适合用 HISA?
A:上下文较短(< 32K)时,indexer 瓶颈不明显,HISA 收益有限。建议先 profile 确认瓶颈再决定是否替换。
Q:HISA 对 block size B 和 top-m 如何调参?
A:论文默认 B=128、top-m=64。更大的 B 减少块级开销但让每个块成为更粗糙的代理;更大的 m 提高质量但增加计算量。
总结
HISA 解决的是大模型长上下文推理中一个被低估的瓶颈——indexer 的 O(L²) 复杂度。通过两阶段分层搜索(block 级初筛 + token 级精筛),它在保持超过 99% 选择质量的前提下:
- 32K 上下文实现 2× 加速
- 128K 上下文实现 4× 加速
- 完全 training-free,可直接替换现有 DSA 模块
随着上下文长度继续增长到 512K、1M,这项技术的价值会更加显著。HISA 的论文已于 2026 年 3 月公开,代码预计开源——值得关注。
参考资料
[1] Xu et al. “HISA: Efficient Hierarchical Indexing for Fine-Grained Sparse Attention”. arXiv:2603.28458v1, 2026. arXiv