DeepSeek V4 突然”开眼”!一篇技术报告公开,284B 开源模型多项基准超越 GPT-5.4
一周前发 V4 时说”多模态在路上”,一周后论文+开源+灰度测试全齐了。关键是——基底模型是 284B 的 Flash,不是 Pro。

导语
4 月 24 日 DeepSeek V4 发布时,官方技术报告里写了一句:”原生多模态能力正在整合中”。
绝大多数人当时的理解是:还得等。
结果 6 天后(4 月 30 日),DeepSeek 联合北京大学、清华大学扔出了一篇技术论文《Thinking with Visual Primitives》,GitHub 同时开源 1。4 月 29 日起,DeepSeek 网页端和 App 开始灰度上线”识图模式”——和”快速模式”、”专家模式”并列一级入口。
更让人意外的是,这个识图功能用的不是 V4 Pro(1.6T),而是 V4 Flash(284B)——参数少了近 6 倍,却在 11 项基准评测中拿下平均 77.2%,多项指标超越了 GPT-5.4、Claude Sonnet 4.6 和 Gemini-3-Flash。
01 DeepSeek”开眼”了:识图模式灰度上线
4 月 29 日开始,部分 DeepSeek 用户在网页端和 App 上看到了第三个模式入口:
快速模式(Flash) | 专家模式(Pro) | 识图模式(Vision) ← NEW
点进去就能上传图片,让 V4 看图分析。
目前已知的能力范围:
| 能力 | 表现 |
|---|---|
| OCR 文字识别 | ✅ 速度快、格式整齐 |
| 网页截图转 HTML | ✅ 非思考模式即可实现 |
| 食品包装/产品识别 | ✅ 能识别品牌、成分、设计特征 |
| 空间推理(数物体、找位置) | ✅ 需开启深度思考 |
| 图片找不同 | ⚠️ 有幻觉,仍在优化 |
值得注意的是——这个识图模式背后的模型,不是 V4 Pro(1.6T 参数),而是 V4 Flash(284B 总参,13B 激活) 2。
为什么一个 13B 激活参数的模型能做到这个程度?答案在下一篇论文里。
02 “视觉原语思考”:把坐标当文字,让 AI 边推理边”指”
4 月 30 日,DeepSeek 联合北京大学、清华大学发布了技术报告《Thinking with Visual Primitives》1。
这篇论文解决了一个核心问题:Reference Gap(指代鸿沟)。
为什么现有 AI 看图说话”说不清”?
传统多模态模型的思维链(Chain of Thought)完全在纯语言空间中运行:
人类:图片左下角那个红色按钮在哪?
AI 思考:用户想找左下角的红色按钮……
AI 输出:在图片左下角的位置。
问题很明显——”左下角”这个词是模糊的。多精确算”左下”?如果图里有三个红色按钮呢?
GPT-5.4、Claude 4.6、Gemini-3-Flash 都在用这种方式。 它们能”看见”图片,但”说不清”物体的精确位置。
DeepSeek 的方案:坐标变成”思维单词”
DeepSeek 的做法很直接——把坐标当成思维链的一部分:
人类:图片左下角那个红色按钮在哪?
AI 思考:用户想找左下角的红色按钮……
<|ref|>红色按钮<|/ref|><|box|>[[120,340,180,380]]<|/box|>
AI 输出:按钮在图中坐标为 (120,340) 到 (180,380) 的位置。
两种”视觉原语”标记:
| 标记 | 用途 | 示例 |
|---|---|---|
<|box|> | 边界框,定位物体 | [[x1,y1,x2,y2]] |
<|point|> | 点坐标,追踪轨迹 | [[x,y], [x,y], ...] |
就像人类边说话边用手指—— AI 在推理的同时输出精确坐标,不再依赖模糊的自然语言描述。
这本质上是一种”多模态思维链”:传统 CoT 在语言空间思考,V4 在”语言+空间”双重空间思考。语言负责逻辑推理,坐标负责精确定位——两者交织在一起,形成完整的”视觉推理能力”。
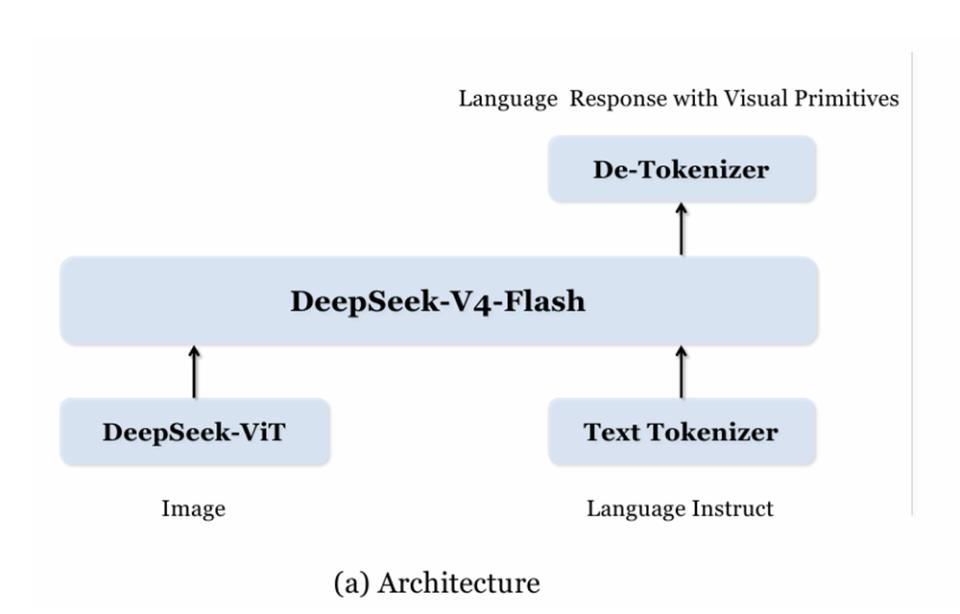
03 7056 倍压缩:为什么 284B 能打 1.6T
多模态模型最大的痛点是视觉 token 太多了。
一张 756×756 的图片,经过 ViT 编码后产生 2916 个 patch token——每个 token 都要参与注意力计算,算力需求爆炸。
DeepSeek 的压缩方案(三步):
原始 ViT 输出:2916 个 token
↓ 3×3 空间压缩
324 个 token
↓ CSA 压缩稀疏注意力
81 个 KV 条目 ← 只有原来的 1/36
总压缩比:7056 倍。
对比其他模型处理 800×800 图片时的 KV Cache 占用:
| 模型 | KV Cache 条目数 |
|---|---|
| DeepSeek V4 Vision | ~90 |
| Gemini-3-Flash | ~1100 |
| Claude Sonnet 4.6 | ~870 |
Claude 要 870 个条目,DeepSeek 只要 90 个——差了近 10 倍。
这就是为什么 284B 的 Flash 能做多模态,还做得比 1.6T 的 Pro 更高效:视觉信息被压到极致,模型把”算力预算”留给了真正的推理。
04 11 项基准评测:多项超越 GPT-5.4
DeepSeek 在 7 项公开基准 + 4 项自建基准上做了全面评测 1。
核心结果:平均得分 77.2%,所有被测模型最高。
| 基准(Benchmark) | DeepSeek V4 Flash | GPT-5.4 | Gemini-3-Flash | Claude 4.6 |
|---|---|---|---|---|
| Pixmo-Count(计数) | 89.2% | 76.6% | 88.2% | 68.7% |
| 细粒度计数 | 88.7% | — | — | — |
| 迷宫导航 | 66.9% | 50.6% | 49.4% | 48.9% |
| 路径追踪 | 56.7% | 46.5% | 41.4% | — |
最值得关注的是迷宫导航和路径追踪——这两项体现的是”空间推理”能力。
其他模型在这两项上都没超过 51%,DeepSeek V4 Flash 分别达到 66.9% 和 56.7%。换句话说:当前所有闭源前沿模型,在空间推理方面的上限还不到 DeepSeek 的及格线。
这印证了论文的核心判断:纯语言思维链无法处理坐标级别的推理。 不把坐标嵌入思维过程,模型就永远”说不清”物体的位置。
05 全部开源 + Apache 2.0
和 V4 一样,多模态框架也走了开源路线:
| 开源内容 | 状态 |
|---|---|
| 论文《Thinking with Visual Primitives》 | ✅ 已发布 |
GitHub 代码仓库 (deepseek-ai/Thinking-with-Visual-Primitives) | ✅ 已公开 |
| 评测基准 | ✅ 部分已开源 |
| 模型权重 | 🔄 “整合后发布” |
| API 多模态接口 | 🔄 后续上线 |
Apache 2.0 协议,免费商用,可微调 3。
06 局限与展望
论文坦白指出了三个当前局限 1:
| 局限 | 说明 |
|---|---|
| 分辨率天花板 | 视觉 token 上限 384,细粒度场景下坐标偶有偏差 |
| 触发词依赖 | 目前需要显式触发词才能激活视觉原语推理,不能自动判断何时用 |
| 拓扑泛化不够 | 迷宫/路径追踪虽大幅领先,但跨场景泛化能力仍有提升空间 |
此外,DeepSeek 近期也面临核心人才流失(多模态、OCR 方向)和首次外部融资(估值超 100 亿美元)等挑战 4。这些因素可能影响后续迭代速度。
但总体而言,作为 V4 系列的第一个多模态版本,这个表现已经远超预期。
总结
V4 完整体的最后一块拼图,现在齐了:
- ✅ Pro(1.6T)——复杂 Agent、高难度编程、深度推理
- ✅ Flash(284B)——极速响应、经济高效
- ✅ Vision(Flash + 视觉原语)——看图、识别、空间推理
一个 284B 的开源模型,用创新的”坐标思维链”方法,在多项视觉基准上超越了 GPT-5.4 和 Claude 4.6。价格不到它们的 1/50,Apache 2.0 开源。
📚 关联阅读
- 《刚刚,DeepSeek V4 来了》 — 必读! 了解 V4 的核心架构升级(CSA 混合注意力、三档推理模式、定价),本文接续那篇讲 V4 的多模态能力
参考资料
[1] DeepSeek, PKU, Tsinghua — Thinking with Visual Primitives — 多模态技术论文及开源代码
[2] DeepSeek 识图模式灰度测试 — 识图模式上线报道
[3] DeepSeek-V4 合集 — Hugging Face — V4 系列模型权重与技术报告
[4] 36氪 — DeepSeek 识图模式实测 — 一手实测报告
[5] 智东西 — DeepSeek”开眼”背后的技术 — 技术解读