Token战争:中国AI大模型如何用”算力成本”反杀硅谷?
导读: 当美国还在讨论AI伦理时,中国大模型已经用”电费优势”悄悄改写了游戏规则。
一、一个惊人的数字:50万亿Token/天
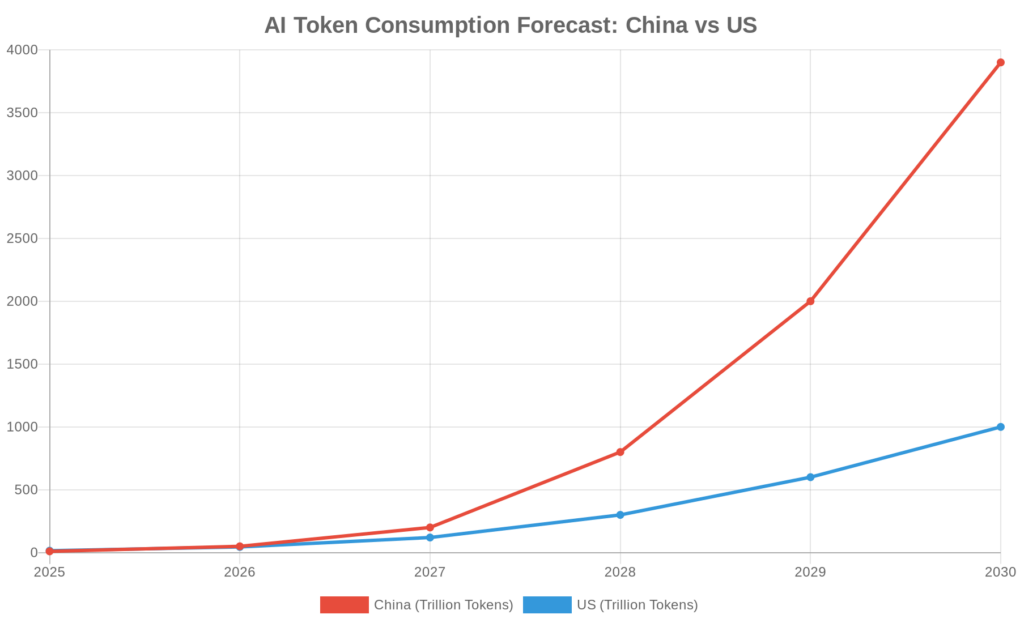
图1:中国vs美国Token消耗量增长趋势(2025-2030)
2026年春节刚过,AI圈被一个数据刷屏了。
字节跳动旗下的豆包大模型(Doubao)日均Token消耗量突破50万亿1,自发布以来实现了400亿倍的高速增长。这意味着什么?意味着每秒钟有数百万用户正在调用豆包进行对话、写作、编程、翻译…
而这只是冰山一角。
根据OpenRouter平台最新数据,2026年2月第三周(2月9日-15日),中国大模型的Token调用量首次超过美国1。在全球Top10大模型中,中国厂商占据6席,MiniMax M2.5、GLM-5的消耗量环比增幅分别高达197%和158%1。
一场关于”Token”的战争,正在悄然改变全球AI格局。
二、Token经济学:为什么中国能赢?
2.1 什么是Token?
简单来说,Token是AI处理信息的最小单位。大模型每生成一个Token,后端服务器就要高速运转,这不仅需要强大的算力,更需要大量的电力。
业内测算,Token生成的成本结构中,电力及算力的成本占比超过70%1。
2.2 中国的”电费优势”
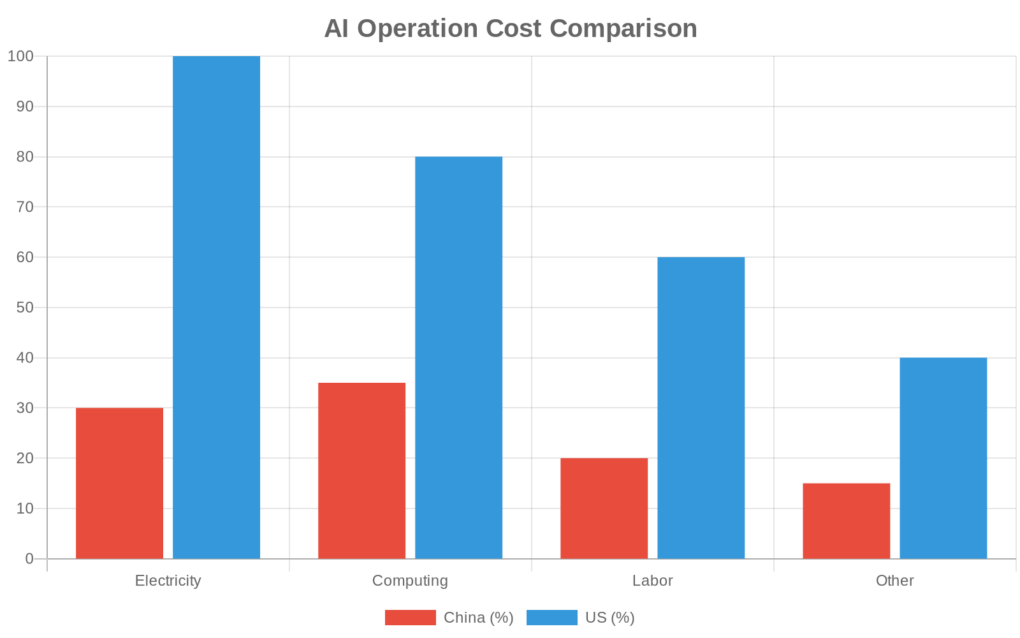
图2:中美AI运营成本对比(中国成本约为美国的30%)
根据国家能源局数据,截至2025年底:
- 我国累计发电装机容量达38.9亿千瓦,同比增长16.1%
- 发电量占全球总量的三分之一
- 成为全球首个全社会用电量突破10万亿千瓦时的国家2
更重要的是价格。摩根大通的报告显示,美国电价呈现明显上涨趋势,而我国电力供给充足且成本优势显著1。
此消彼长之下,同样的AI服务,在中国运行的成本可能只有美国的三分之一甚至更低。
2.3 DeepSeek的”1%奇迹”
如果说豆包代表了应用层的爆发,那么DeepSeek则证明了技术层的可能。
这家小型创业公司,仅用1%的算力就达到了和美国前沿大模型相似的能力2。其核心创新在于:
- 算法层面的深度优化
- 系统架构的重新设计
- 训练流程的工程创新
DeepSeek的出现,让中美在大模型领域的差距从”2-3年”缩短到”2-3个月”2。
更值得关注的是,DeepSeek采用开源模式,很快被那些买不起大模型的国家、地区所使用,这使得整个模型的落地和应用变得越来越快2。
三、开源生态:中国玩家的”群狼战术”
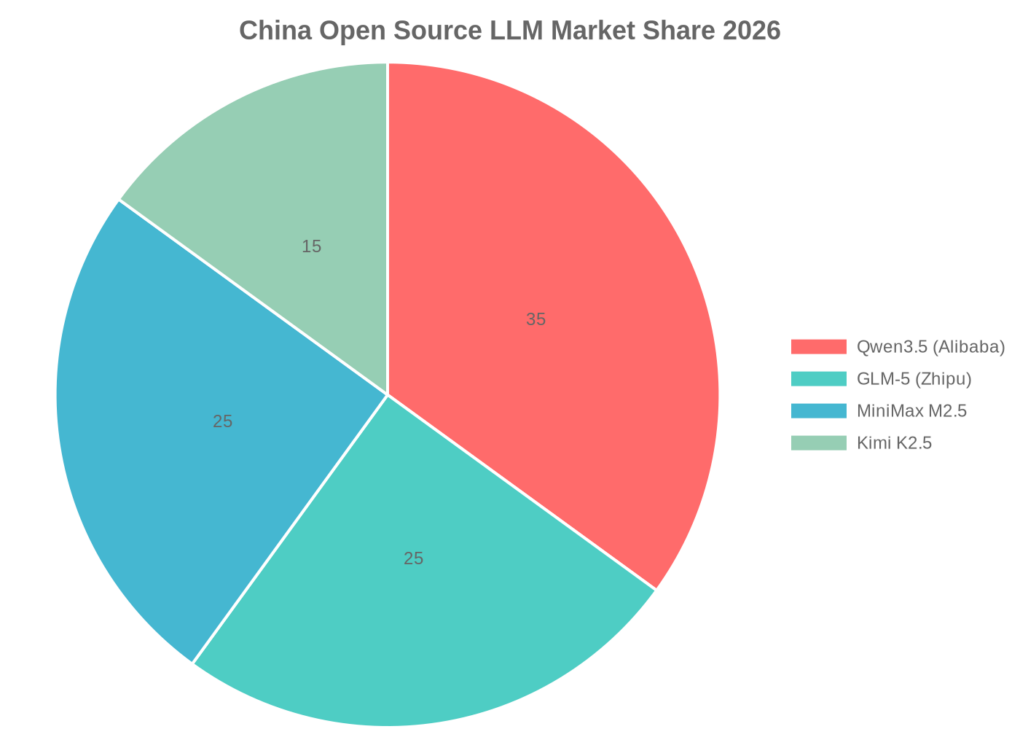
图3:中国四大开源模型市场份额分布
2026年2月25日,阿里云百炼推出重磅计划:Qwen3.5、GLM-5、MiniMax M2.5、Kimi K2.5四大顶尖开源模型API服务正式上线3。
这不是简单的技术开放,而是一场精心设计的生态战争。
| 厂商 | 核心策略 | 最新动态 |
|---|---|---|
| 阿里 | 开源+云生态 | Qwen系列Hugging Face下载量持续领先4 |
| 智谱 | B端MaaS服务 | GLM-5技术报告公开,本地部署收入达84.8%1 |
| MiniMax | C端多模态产品 | 海外收入占比超70%,日耗Token超5万亿1 |
| 月之暗面 | 长文本+Agent | Kimi K2成为首个开源agentic model5 |
四家厂商走出差异化路径,却形成了同一个结果:中国开源大模型生态正在成为全球开发者的首选。
以阿里为例,2025年4月发布并开源Qwen3系列,一次性推出8款开源模型,涵盖多种参数规模。此前3月已开源QwQ-32B推理模型,性能比肩DeepSeek-R1。Qwen系列在Hugging Face下载量持续领先,成为全球最受欢迎的开源大模型之一4。
智谱则走出另一条路。2025年12月,智谱完成股改,冲刺”全球大模型第一股”。其GLM-5技术报告全面公开,正面回应”套壳””蒸馏海外模型”等质疑,展现出技术自信1。
四、Token出海:369倍增长空间
当国内市场竞争白热化,”Token出海”成为新的增长点。
数据显示,MiniMax的海外收入占比已超过70%1,其M2.5模型在海外市场广受欢迎。更值得关注的是,中国AI推理Token消耗量预计将从2025年的约10千万亿增长至2030年的约3900千万亿,增幅接近369倍1。
这一增长主要由两个因素推动:
第一,AI渗透率持续提升。 随着AI成为搜索、内容生成、客户服务和生产力的默认界面,AI在消费者用户和企业工作负载中的渗透率都在快速提高。
第二,用例不断扩展。 从对话AI扩展到智能体和多模态输出——更长的上下文、更多的工具调用、更丰富的输出。即使用户数量增长放缓,这也会实际增加每个会话的Token消耗。
从细分领域来看,随着时间推移,推理需求的占比发生明显变化。对话AI占2025年预期Token总消耗量的近一半,预计到2030年逐步下降至高个位数百分比;生活场景AI智能体的份额预计将从2025年的个位数提高至2030年的10%到20%1。
五、全球格局:从”跟跑”到”并跑”再到”领跑”
5.1 大模型排行榜的重塑
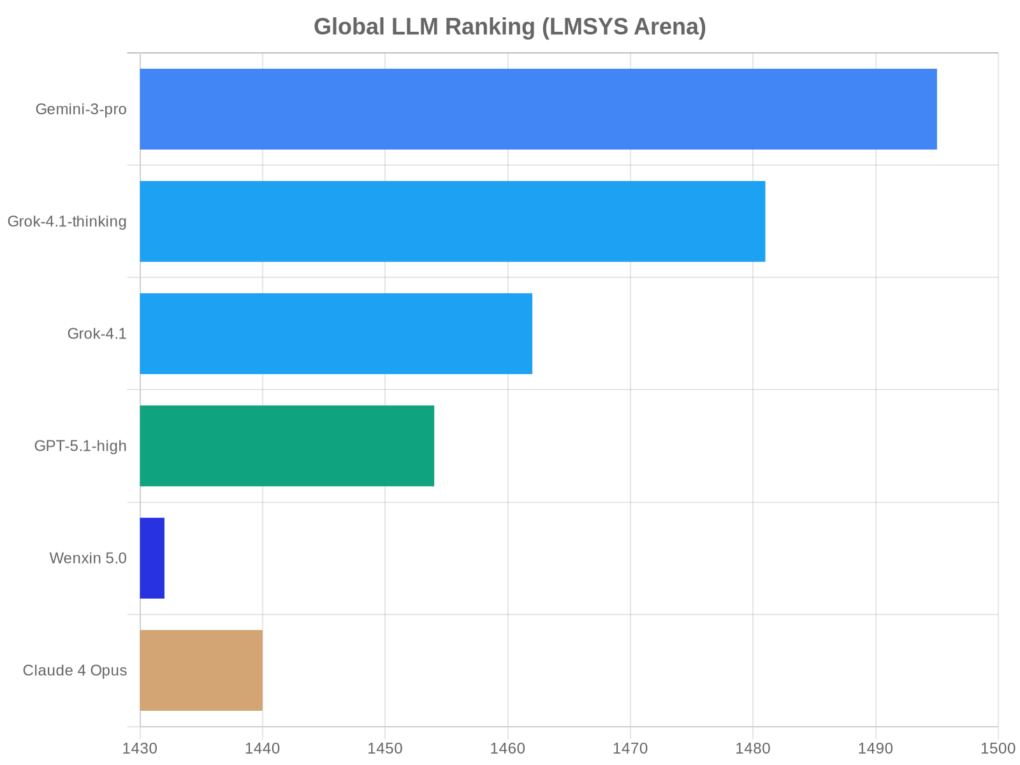
图4:LMSYS Chatbot Arena全球大模型排行榜
根据LMSYS Chatbot Arena 2025年11月最新数据,全球排名前20的AI大模型呈现激烈竞争态势4:
- Google Gemini-3-pro(1495分)全面领先
- xAI Grok-4.1-thinking(1481分)紧随其后
- xAI Grok-4.1(1462分)
- OpenAI GPT-5.1-high(1454分)
- Google Gemini-2.5-pro(1451分)
值得注意的是,百度文心5.0 Preview以1432分位居国内第一,在多模态能力上优于GPT-4o,API价格仅为竞品11%4。
5.2 中国力量的集体崛起
2025年7月,2025世界人工智能大会(WAIC 2025)在上海举办,展览面积超7万平方米,参展企业超800家,展品超3000件。腾讯发布混元3D世界模型1.0,商汤发布日日新V6.5,多家企业集中展示最新成果4。
大会聚焦大模型、具身智能等前沿领域,成为全球AI产业风向标。
5.3 第四次工业革命的领军者
清华大学智能产业研究院院长张亚勤教授在近期演讲中指出:
“在前三次工业革命中,中国始终是旁观者或跟随者,而人工智能带来了新的无尽的前沿,正在开启第四次工业革命。这一次,我坚信,凭借强大的国力、众多的人才和有利的政策,中国必将成为第四次工业革命的领军者!”2
这不是盲目乐观。
从技术层面看,中国在多模态、Agent、企业级应用等前沿领域已全面布局6; 从产业层面看,算力总规模跃居全球第二,关键硬件环节基本实现自主可控1; 从市场层面看,庞大的用户基数和丰富的应用场景,为技术迭代提供了天然土壤。
六、未来展望:Token战争的下一站
6.1 算力成本的持续优化
华为重磅推出参数量规模高达7180亿的全新模型——盘古Ultra MoE,这是全流程在昇腾AI计算平台上训练的准万亿MoE模型,标志着基于昇腾架构可打造世界一流大模型,实现从硬件到软件的全栈国产化闭环4。
6.2 智能体(Agent)的新战场
2025年11月6日,月之暗面发布Kimi K2 Thinking推理模型,作为中国首个万亿参数基座模型和第一个开源的agentic model,号称原生掌握”边思考,边使用工具”的能力5。
张亚勤教授认为:”智能体是实现通用人工智能(AGI)的必然路径。目前通用人工智能的定义尚未统一,我的理解是:具有可进化、可泛化和长期记忆的智能体,在执行99%的任务上超过99%的人类。如果按这样的定义,我认为有望在15-20年内达到通用人工智能的水平。”2
6.3 Token出海的战略意义
摩根大通预测,基于用户情境的预测,从应用采用的角度出发,Token消耗量或将开启多年增长期。中国的AI推理Token消耗量预计将从2025年的约10千万亿增长至2030年的约3900千万亿,增幅接近369倍1。
对于开发者而言,性价比是硬道理。从国内来看,无论是电力还是算力,都具备显著的成本优势,并有望重构AI定价权。
结语:当硅谷还在讨论伦理,我们已经动手了
AI的竞争,最终是成本的竞争、效率的竞争、落地能力的竞争。
当美国科技巨头还在为AI伦理争论不休时,中国厂商已经用”电费优势”和”工程能力”,在全球范围内赢得了第一批用户。
从DeepSeek的”1%奇迹”到豆包的”50万亿Token”,从阿里的开源生态到MiniMax的出海成功,中国AI正在用实实在在的数据证明:
在这场Token战争中,我们不仅有参与权,更有话语权。
Token战争,才刚刚开始。而中国,已经占据了有利地形。
参考来源
[4] 2025人工智能大事件回顾 – 清华AI国际治理研究院