挑战英伟达!24人团队造出AI芯片,速度快50倍、功耗降10倍
引言
2026年2月21日,一家名为 Taalas 的芯片初创公司正式发布了它的第一款产品:HC1 —— 一颗将 Meta 的 Llama 3.1 8B 大语言模型几乎完整”刻进”硅片的推理芯片12。
按照该公司公布的数据,这款芯片在单用户场景下可以达到 每秒 17,000 tokens 的推理速度,是当前市场最快竞品 Cerebras 的近 9 倍,较英伟达 Blackwell 架构 GPU 快近 50 倍3。同时,其构建成本据称只有同等 GPU 方案的二十分之一,功耗降低一个数量级4。
更令人惊讶的是:这家公司只有 24 人,成立仅 2.5 年,研发这款芯片只用了约 3000 万美元5。
HC1 芯片:硬核规格

基础参数
芯片型号: HC1
适配模型: Llama 3.1 8B (80亿参数)
芯片面积: 815 mm²
制造工艺: 台积电 N6
晶体管数量: 530亿
团队规模: 约24人
研发投入: 约3000万美元
性能表现
单芯片性能:HC1 在运行 Llama 3.1 8B 模型时,实测推理速度达到 每秒 16,960 tokens6。
集群性能:对于更大的模型,如 DeepSeek R1 67B,约需 30 颗 HC1 芯片协同工作,可实现每秒 12,000 tokens 的单用户吞吐7。
功耗与成本
| 项目 | HC1 | 传统GPU方案 |
|---|---|---|
| 单卡功耗 | 250W | 需液冷散热8 |
| 10卡集群 | 2.5kW(风扇即可) | 接近 120kW8 |
| 构建成本 | GPU方案的 1/20 | –4 |
| 每百万tokens成本 | $0.0075 | ~$0.156 |
技术原理:为什么这么快?
传统GPU的瓶颈
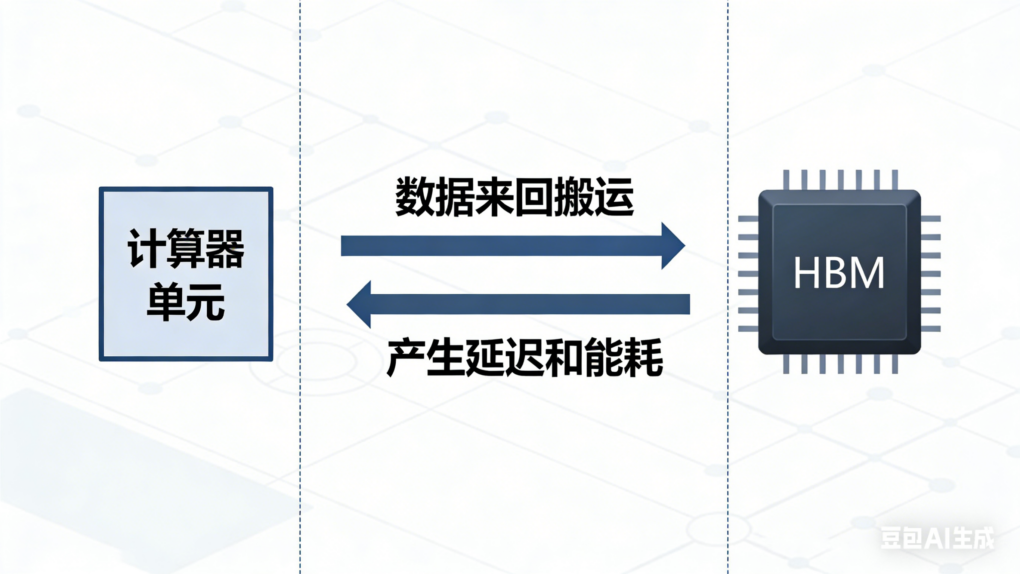
当前主流的 AI 推理部署依赖 GPU,尤其是英伟达的 H100/H200 和最新的 Blackwell 系列。然而,GPU 的架构天然存在一个瓶颈:计算单元和存储单元是分离的9。
模型的参数存储在 HBM(高带宽内存)中,计算核心每次运算都需要从 HBM 搬运数据,这个搬运过程消耗大量能量和时间10。
Taalas 的创新:硬编码推理
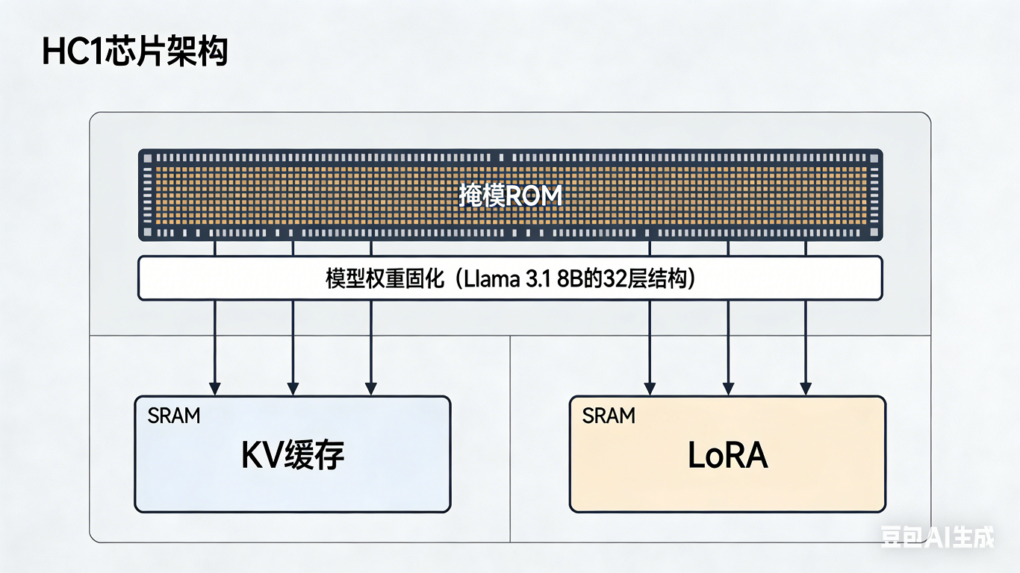
Taalas 采用了极端的专用化设计,将 AI 模型的部分结构直接刻制在硅片上2:
核心特点:
- 模型权重直接固化于掩模 ROM(Mask ROM)中,与计算逻辑单元共存于同一硅片10
- 完全摒弃外部 DRAM 或 HBM,仅保留小容量 SRAM 用于存储键值缓存和低秩适配微调权重10
- 电信号直接流动,无需存取操作
生产流程
Taalas 的创新在于采用”结构化专用集成电路”的定制化思路,但将专用化程度推向新高度10:
- 先完成约 100 层结构的芯片制造(近乎完整)
- 在最后 2 层金属层上进行最终定制化2
- 从模型交付到生成寄存器传输级(RTL)设计仅需 1 周 工程时间10
- 完整流片周期可压缩至 2 个月10
相比之下,英伟达 Blackwell 这类 AI 处理器的生产周期约为 6 个月4。
性能对比:HC1 vs 其他方案

推理速度对比(实测数据)
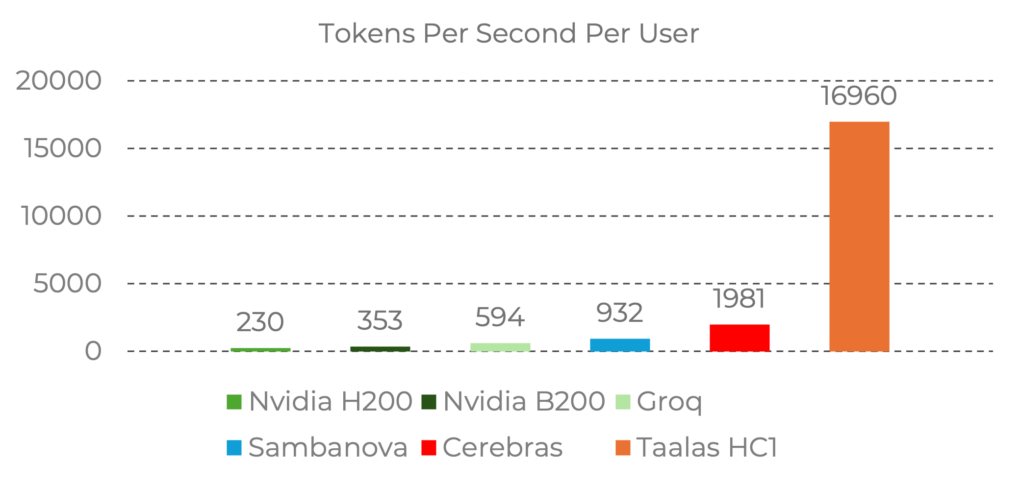
在 Llama 3.1 8B 基准测试(输入序列 1k/1k)中6:
| 芯片/方案 | tokens/s | 相对HC1 |
|---|---|---|
| Taalas HC1 | 16,960 | 1x |
| NVIDIA H200 | 230 | ~74x slower |
| NVIDIA B200 | 353 | ~48x slower |
| Groq | 594 | ~29x slower |
| SambaNova | 932 | ~18x slower |
| Cerebras | 1,981 | ~9x slower |
数据来源:Taalas 官方基准测试数据6
可视化对比
局限性与挑战
明显的短板
HC1 芯片的局限也非常明显,它只能跑 Llama 3.1 8B9。要想换个模型,就只能再造一颗芯片。
这是 AI 芯片行业迄今为止最激进的专用化尝试,没有之一9。
具体限制包括:
| 限制项 | 描述 |
|---|---|
| 不可编程 | 芯片出厂后无法更改模型 |
| 不支持训练 | 专门用于推理,不支持模型训练 |
| 不支持多模态 | 专注于文本生成 |
| 长链推理表现一般 | 网友试测:o1 风格的长链推理有卡顿11 |
适用场景分析
适合:
- 模型版本稳定的生产环境
- 推理即服务(Inference-as-a-Service)
- 对延迟敏感的应用
- 大规模部署(成本优势明显)
不适合:
- 模型频繁迭代
- 需要多模型支持
- 研发实验阶段
- 需要多模态能力
团队与融资
团队背景
Taalas 由 前 AMD 高管 Ljubisa Bajic 创立7。核心团队约 24 人,公开资料显示为 25 名员工7。
Ljubisa Bajic 曾在 AMD、英伟达担任骨干架构师,也是明星 AI 芯片公司 Tenstorrent 的创始人,曾与 Jim Keller 共同研发过异构计算架构11。
融资情况
| 时间 | 融资轮次 | 金额 |
|---|---|---|
| 早期 | – | 约 5000 万美元12 |
| 2026年2月 | 最新融资 | 1.69 亿美元1 |
| 累计 | – | 超过 2 亿美元5 |
行业影响与未来展望
对英伟达的挑战
Taalas 的成功证明了极端专用化路线的可行性11:
“我们不应该在通用计算机上模拟智能,而应该直接在芯片中打造智能。”
—— Ljubisa Bajic,Taalas CEO12
产品路线图
2026 Q2:
- HC1 芯片开始交付客户
2026冬季:
- HC2 芯片发布
- 支持更大规模模型
- 多芯片互联技术
2026年底:
- 支持GPT-5.2等顶级大模型的处理器
潜在挑战
- 生态壁垒:英伟达 CUDA 生态根深蒂固
- 通用性限制:只能运行特定模型
- 市场教育:需要说服客户切换技术路线
- 量产能力:能否保证良率和交付
结语
Taalas HC1 的故事告诉我们:专用化 + 极致优化 = 颠覆性性能。
虽然 HC1 有明显的局限性,但它在特定场景下的表现确实令人惊叹。这或许就是 AI 芯片未来的一个方向:
与其追求通用性,不如在特定场景下做到极致。
参考文献
[1] 新浪财经. 芯片初创公司Taalas融资1.69亿美元,研发AI芯片挑战英伟达. 2026-02-20. https://www.sina.com.cn/article_7857201856_1d45362c001902htz0.html
[2] 虎嗅. Taalas融资1.69亿美元研发AI芯片,挑战英伟达. 2026-02-20. https://www.huxiu.com/ainews/8957.html
[3] DeepTech深科技. 初创用3000万造不可编程的AI芯片,推理速度是Nvidia最强GPU 50倍. 2026-02-21. https://www.163.com/dy/article/KMAGMB0D05568W0A.html
[4] 新浪财经. 初创公司Taalas押注极端专用化:3000万造AI芯片,推理速度远超GPU. 2026-02-22. https://k.sina.com.cn/article_7857201856_1d45362c001902j0au.html
[5] 什么值得买. 加拿大AI初创Taalas发布专用推理芯片HC1. 2026-02-21. https://post.m.smzdm.com/p/agopvn8w/
[6] 今日头条. AI推理新纪元:Taalas硬核芯片将模型固化,速度升10倍成本降20倍. 2026-02-21. https://m.toutiao.com/article/7609202902862725674
[7] EE Times. Taalas Specializes to Extremes for Extraordinary Token Speed. 2026-02-19. https://www.eetimes.com/taalas-specializes-to-extremes-for-extraordinary-token-speed/
[8] 网易新闻. GPU要凉?前英伟达AMD大神将AI刻在芯片上!17000 tokens/秒屠榜. https://c.m.163.com/news/a/KMCTT4ID0511ABV6.html
[9] 腾讯新闻. 初创用3000万美元造一颗不可编程的AI芯片,推理速度却是Nvidia最强GPU的50倍. 2026-02-21. https://new.qq.com/rain/a/LNK2026022111361400
[10] 搜狐. 初创公司Taalas押注极端专用化:3000万美元造AI芯片 性能碾压GPU. 2026-02-21. https://m.sohu.com/a/988944101_362225
[11] 今日头条. Llama 3.1跑出17000 token/s小公司干翻一众巨头,芯片还能升级吗?. 2026-02-21. https://m.toutiao.com/article/7609237522647925275/
[12] CSDN. Taalas 芯片:大语言模型推理新突破. 2026-02-22. https://blog.csdn.net/techforward/article/details/158289907
本文为原创内容,数据来源于公开报道,转载请注明出处。
关注我们,获取更多AI芯片行业深度解读。